
Продовжуємо публікацію короткого курсу наших колег: після загальних відомостей, основ багатопотокових програм, блокувань та інших методів синхронізації потоків поговоримо про пули потоків і чергу задач.
4.1 ПУЛИ ПОТОКІВ RUNNABLE І CALLABLE
Створення потоків для виконання великої кількості задач є дуже трудомістким: створення потоку та звільнення ресурсів — дорогі операції. Для розв’язання проблеми було введено пули потоків і черги задач, з яких беруться задачі для пулів. Пул потоків — своєрідний контейнер, в якому містяться потоки, що можуть виконувати задачі та після виконання однієї самостійно переходити до наступної.
Друга причина створення пулів потоків — можливість розділити об'єкт, що виконує код, і безпосередньо код задачі, яку необхідно виконати. Використання пулу потоків:
- забезпечує кращий контроль створення потоків;
- економить ресурси створення потоків;
- спрощує розробку багатопотокових програм, спрощуючи створення та маніпулювання потоками.
За створенням і управлінням пулом потоків відповідають декілька класів та інтерфейсів, які називаються Executor Framework in Java.
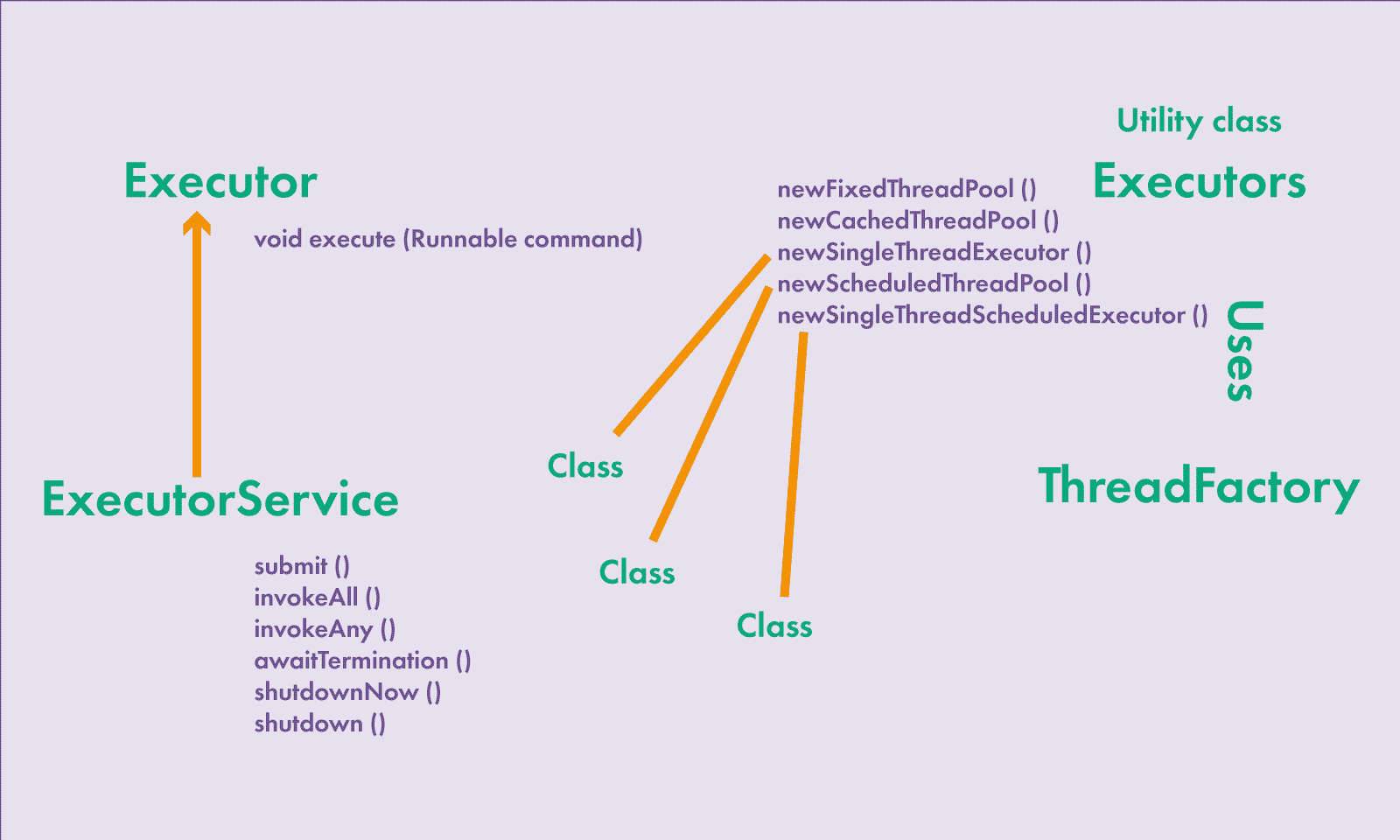
Малюнок 1: Спрощене схематичне уявлення класів, що відповідають за пул потоків
Примітки до малюнка 1. Це не схема успадкування класів і не UML-діаграма, а проста структурна схема, яка показує, хто що використовує, які є методи і що виходить у підсумку.
Розглянемо основні інтерфейси та класи, що входять до цього фреймворку. Його основні інтерфейси: Executor, ExecutorService і фабрика Executors. Об'єкти, які реалізують інтерфейс Executor, можуть виконувати runnable-задачі. Інтерфейс Executor має один метод void execute(Runnable command). Після виклику цього методу та передачі задачі на виконання задачу в майбутньому буде виконано асинхронно. Також цей інтерфейс розділяє, хто виконуватиме задачу та що виконуватиметься, — на відміну від класу Thread.
Інтерфейс ExecutorService успадковується від інтерфейсу Executor і надає можливості для виконання задач Callable, для переривання виконуваної задачі та завершення роботи пулу потоків. Для виконання задач, які повертають результат, існує метод submit(), який повертає об'єкт, що реалізує інтерфейс Future. За допомогою цього об'єкта можна дізнатись, чи є результат, викликом методу isDone(). За допомогою методу get() можна отримати результат виконання задачі, якщо він є. Також можна скасувати задачу на виконання за допомогою методу cancel().
Клас Executors — утилітний клас, як наприклад, клас Collections. Клас Executors створює класи, що реалізують інтерфейси Executor і ExecutorService. Основні реалізації пулу потоків, тобто реалізації інтерфейсів Executor і ExecutorServcie:
- ThreadPoolExecutor — пул потоків, що містить фіксовану кількість потоків. Також цей пул можна створити з використанням конструктора через ключове слово new.
- Executors.newCachedThreadPool() повертає пул потоків, якщо в пулі не вистачає потоків, у ньому буде створено новий потік.
- Executors.newSingleThreadExecutor() — пул потоків, в якому є тільки один потік.
- ScheduledThreadPoolExecutor — цей пул потоків дозволяє запускати завдання з певною періодичністю або один раз після закінчення проміжку часу.
4.2 ThreadFactory
Пул потоків використовує клас, який реалізує інтерфейс ThreadFactory для створення потоків, щоб один потік міг виконувати кілька Runnable- або Callable-об'єктів. Потік, що виконує кілька об'єктів Runnable, називається Worker. Ланцюжок виконання такий: ThreadPoolExecutor -> Thread -> Worker -> YourRunnable. За замовчуванням використовується клас Executors$DefaultThreadFactory. ThreadFactory — інтерфейс з одним методом Thread newThread(Runnable r). Стандартно іменування потоків у пулі потоків pool-n-thread-m. Клас, який реалізує ThreadFactory, використовується, щоб налаштувати потік для пулу потоків. Наприклад, встановити ім'я чи пріоритет потоку, встановити ExceptionHandler для потоку або зробити потоки всередині Executor демонами.
4.3 ЗАВЕРШЕННЯ ВИКОНАННЯ ПУЛУ ПОТОКІВ
Для завершення роботи пулу потоків інтерфейс ExecutorService має декілька методів: shutdown(), shutdownNow() і awaitTermination(long timeout, TimeUnit unit).
Після виклику методу shutdown() пул потоків продовжить роботу, але при спробі передати на виконання нові задачі їх буде відхилено та буде згенеровано RejectedExecutionException.
Метод shutdownNow() не запускає нові задачі, які вже було встановлено на виконання, та намагається завершити вже запущені.
Метод awaitTermination(long timeout, TimeUnit unit) блокує потік, який викликав цей метод, поки всі задачі не виконають роботу, або поки не закінчиться таймаут, переданий при виклику методу, або поки поточний потік, що очікує, не буде перервано. Загалом, поки якась із цих умов не виконається першою.
4.4 СКАСУВАННЯ ЗАДАЧ У EXECUTORS
Після передачі Runnable або Callable повертається об'єкт Future. Цей об'єкт має метод cancel(), що може використовуватися для скасування завдання. Виклик цього методу має різний ефект у залежності від того, коли було викликано метод. Якщо метод було викликано, коли задача ще не почала виконуватись, задача просто видаляється з черги задач. Якщо задачу вже виконано, виклик методу cancel() не призведе до жодних результатів.
Найцікавіший випадок виникає, коли задача знаходиться у процесі виконання. Задача може не зупинитись, тому що у Java задачі покладаються на механізм переривання потоку. Якщо потік не проігнорує цей сигнал, потік зупиниться. Однак він може й не відреагувати на сигнал переривання.
Іноді необхідно реалізувати нестандартне скасування виконання задачі. Наприклад, задача виконує блокуючий метод на кшталт ServerSocket.accept(), який очікує на підключення якогось клієнта. Цей метод ігнорує будь-які перевірки прапора interrupted. У представленому вище випадку для зупинки задачі необхідно закрити сокет, при цьому виникне виключення, яке слід обробити. Існують два способи реалізації нестандартного завершення потоку. Перший — перевизначення методу interrupt() у класі Thread, який не рекомендується використовувати. Другий — перевизначення методу Future.cancel(). Однак об'єкт Future є інтерфейсом, і об'єкти, що реалізують цей інтерфейс, користувач не створює вручну. Значить, треба знайти спосіб, який дозволить це зробити. І такий спосіб існує. Об'єкт Future повертається після виклику методу submit(). Під капотом ExecutorService викликає метод newTaskFor(Callable c) для отримання об'єкта Future. Метод newTaskFor варто перевизначити, щоб він повернув об'єкт Future з потрібною функціональністю методу cancel().
Лістинг 1:
import java.util.concurrent.BlockingQueue;
public class CustomFutureReturningExecutor extends ThreadPoolExecutor {
public CustomFutureReturningExecutor(int corePoolSize,
int maximumPoolSize, long keepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
if (callable instanceof IdentifiableCallable) {
return ((IdentifiableCallable<T>) callable).newTask();
} else {
return super.newTaskFor(callable);
}
}
}
Лістинг 2:
import java.util.concurrent.*;
public interface IdentifiableCallable<T> extends Callable<T> {
int getId();
RunnableFuture<T> newTask();
void cancelTask();
}
Далі необхідно визначити клас FutureWarapper, щоб можна було перевизначити метод cancel();
Лістинг 3:
import java.util.concurrent.*;
public abstract class FutureTaskWrapper<T> extends FutureTask<T> {
public FutureTaskWrapper(Callable<T> c) {
super(c);
}
abstract int getTaskId();
}
Клас FutureTask реалізує одночасно Runnable і Callable. Цей клас представляє базову реалізацію інтерфейсу Future і призначений для додавання нової функціональності. Далі слід визначити завдання, яке виконуватиметься в Executor.
Лістинг 4:
class Task implements IdentifiableCallable<Boolean> {
private final int id;
volatile boolean cancelled; // Cancellation flag
public Task(int id) {
this.id = id;
}
@Override
public synchronized int getId() {
return id;
}
@Override
public RunnableFuture<Boolean> newTask() {
return new FutureTaskWrapper<Boolean>(this) {
@Override
public boolean cancel(boolean mayInterruptIfRunning) {
Task.this.cancelTask();
return super.cancel(mayInterruptIfRunning);
}
@Override
public int getTaskId() {
return getId();
}
};
}
@Override
public synchronized void cancelTask() {
cancelled = true;
}
@Override
public Boolean call() {
while (!cancelled) {
// Do Samba
}
System.out.println("bye");
return true;
}
}
У лістингу 4 з методу newTask() повертається клас, успадкований від класу FutureTaskWrapper. У конструктор цього класу передається посилання this (об'єкт Callable), необхідне для коректного створення об'єкта Futuretask. У лістингу 5 наведено код головного класу програми, який запускає вдосконалений ExecutorService.
Лістинг 5:
import java.util.concurrent.*;
public class FutureTaskWrapperConcept {
public static void main(String[] args) throws Exception {
ExecutorService exec = new CustomFutureReturningExecutor(1, 1,
Long.MAX_VALUE, TimeUnit.DAYS,
new LinkedBlockingQueue<Runnable>());
Future<?> f = exec.submit(new Task(0));
FutureTaskWrapper<?> ftw = null;
if (f instanceof FutureTaskWrapper) {
ftw = (FutureTaskWrapper<?>) f;
} else {
throw new Exception("wtf");
}br
try {
Thread.sleep(2000);
} catch (InterruptedException ignored) {
}br System.out.println("Task Id: " + ftw.getTaskId());
ftw.cancel(true);
exec.shutdown();
}
}
Тепер при виклику методу cancel() буде виконано нестандартну логіку зі скасування задачі.
4.5 ОБРОБКА ВИКЛЮЧЕНЬ
Для обробки виключень, які виникають при виконанні об'єктів Runnable, встановлюється обробник винятків у ThreadFactory, потім ThreadFactory встановлює потоки.
Лістинг 6:
public class ExceptionHandler implements Thread.UncaughtExceptionHandler {
@Override
public void uncaughtException(Thread thread, Throwable t) {
System.out.println("Uncaught exception is detected! " + t + " st: " +
Arrays.toString(t.getStackTrace()));
}
}
public class CustomThreadFactory implements ThreadFactory {
private final Thread.UncaughtExceptionHandler handler;
public CustomThreadFactory(Thread.UncaughtExceptionHandler handler) {
this.handler = handler;
}
@Override
public Thread newThread(Runnable run) {
Thread thread = Executors.defaultThreadFactory().newThread(run);
thread.setUncaughtExceptionHandler(handler);
return thread;
}
}
public class ExceptionHandlerExample {
public static void main(String[] args) throws InterruptedException {
ThreadFactory threadFactory =
new CustomThreadFactory(new ExceptionHandler());
ExecutorService threadPool =
Executors.newFixedThreadPool(4, threadFactory);
Runnable r = () -> {
throw new RuntimeException("Exception from pool");
};
threadPool.execute(r);
threadPool.shutdown();
threadPool.awaitTermination(10, TimeUnit.SECONDS);
}
}
У лістингу 6 створюється обробник виключень, який передається фабриці потоків. Створюється пул із чотирьох потоків з використанням переданої фабрики. При виникненні виключення воно перехоплюється обробником виключення ExceptionHandler. Такий спосіб підходить, коли пул потоків виконує задачі Runnable. Якщо виняток виникає при виконанні завдання Callable, при отриманні значення з об'єкта Future буде згенеровано ExecutionException. Приклад у лістингу 7.
Лістинг 7:
import java.util.concurrent.*;
public class ExceptionFromFutureObject {
public static void main(String[] args) throws InterruptedException {
ExecutorService threadPool3 = Executors.newFixedThreadPool(4);
Callable<String> c3 = () -> {
throw new Exception("Exception from task.");
};
Future<String> executionResult = threadPool3.submit(c3);
threadPool3.shutdown();
threadPool3.awaitTermination(10, TimeUnit.SECONDS);
try {
executionResult.get();
} catch (ExecutionException e) {
Throwable cause = e.getCause();
System.out.println(cause.getMessage());
}
}
}
Ще один спосіб обробки винятків у ExecutorService — використання Callable. Якщо успадковуватися від класу ThreadPoolExecutor, потрібно врахувати, що він має так звані hook-методи: void beforeExecute(Thread t, Runnable r) і void afterExecute(Thread t, Runnable r). Ці методи виконуються тим потоком, який виконуватиме безпосередньо саме завдання. Якщо перевизначити метод afterExecute(), виключення, які буде згенеровано в процесі виконання завдання, можна буде обробити в методі afterExecute. Приклад у лістингу 8.
Лістинг 8:
class ExtendedExecutor extends ThreadPoolExecutor {
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
if (t == null && r instanceof Future<?>) {
try {
Object result = ((Future<?>) r).get();
} catch (CancellationException ce) {
t = ce;
} catch (ExecutionException ee) {
t = ee.getCause();
} catch (InterruptedException ie) {
Thread.currentThread().interrupt(); // ignore/reset
}
}
if (t != null) {
System.out.println(t);
}
}
}
4.6 Клас ThreadPollExecutor
Один з основних класів, які генерує фабрика Executors, — клас ThreadPoolExecutor. Розглянемо основні параметри цього класу.
Параметри core and maximum pool size. ThreadPoolExecutor автоматично налаштує розмір пулу потоків відповідно до встановлених значень corePoolSize і maximumPoolSize. Коли пулу потоків передається нова задача, а кількість працюючих потоків менше, ніж corePoolSize, створюється новий потік, навіть коли інші потоки нічого не роблять. Якщо кількість запущених потоків більше, ніж corePoolSize, але менше, ніж maximumPoolSize, новий потік буде створено, якщо черга задач заповнена. Якщо значення параметрів corePoolSize і maximumPoolSize рівні, створюється пул потоків фіксованого розміру. Якщо в якості параметра maximumPoolSize передається необмежене значення, наприклад, Integer.MAX_VALUE, це дозволяє пулу потоків виконувати довільну кількість задач. Клас ThreadPoolExecutor, як і інші класи пулу потоків, використовує чергу задач для передачі та утримання задачі для пулу потоків.
При роботі з чергою задач використовують такі правила:
- якщо кількість задач менше, ніж параметр corePoolSize, пул потоків завжди віддасть перевагу запуску нового потоку;
- якщо кількість працюючих потоків більше або дорівнює параметру corePoolSize, пул потоків віддасть перевагу поміщенню задачі в чергу;
- якщо задачу не можна помістити в чергу, пул потоків спробує створити новий потік;
- якщо кількість створених потоків перевищує значення maximumPoolSize, задачу буде відхилено та передано RejectedExecutionHandle для подальшої обробки.
4.7 Fork/Join Pool
Із виходом Java 7 в арсеналі розробників з'явився новий фреймворк Fork/Join Pool. У Java 8 Fork/Join pool створюється за замовчуванням, коли ми викликаємо метод parallel() для паралельної обробки даних. Також Fork/Join pool використовується у класі CompletableFuture. Клас ForkJoinPool реалізує інтерфейси Executor, ExecutorService. Клас ForkJoinPool можна створити через ключове слово new і через клас Executors.newWorkStealingPool().
ForkJoinPool використовує спосіб, коли одна задача поділяється на декілька дрібних, що виконуються окремо, а потім отримані відповіді об'єднуються в єдиний результат. У Fork/Join Pool є багато методів, проте використовуються здебільшого три: fork(), compute() і join(). Метод compute() містить спочатку велику задачу, яку необхідно виконати. У методі compute() використовується один і той самий шаблон: якщо задача занадто велика, вона розбивається на дві або більше підзадач; якщо задача досить маленька, відповідно до умов, заданих програмістом, вона виконується в методі compute(). Приклад псевдокоду — в лістингу 9.
Лістинг 9:
if(Task is small) {
Execute the task
} else {
//Split the task into smaller chunks
ForkJoinTask first = getFirstHalfTask();
first.fork();
ForkJoinTask second = getSecondHalfTask();
second.compute();
first.join();
}
До кожного потоку, який правильніше було б називати воркером, у Fork/Join пулі призначено чергу — dequeue. Спочатку черги є порожніми, і потоки в пулі без роботи. Передана у Fork/Join pool основна задача (top-level) поміщається в чергу, призначену для top-level задач. Для цього процесу існує окремий потік, який запускає ще кілька потоків, що безпосередньо братимуть участь в обробці підзадач. Це зроблено, щоб не витрачати час на запуск потоків Fork/Join пулу в подальшому. Усереднений час запуску потоку на операційних системах типу Linux на JVM — близько 50 мкс. Однак якщо запускати кілька потоків одночасно, часу потрібно більше, а для деяких застосунків навіть зовсім невелика затримка виявляється критичною.
Після виклику методу fork() задачу буде розбито на дві або більше підзадач і поміщено в чергу поточного потоку. Отримані задачі кладуться в голову черги. Поточний потік також отримує задачі з голови черги. Цей підхід застосовується, щоб потік працював зі своєю чергою без синхронізації. Інші потоки, які хочуть вкрасти задачі з черги, отримують задачі з хвоста черги — там використовується синхронізація.
У псевдокоді в лістингу 9 викликається метод compute() для виконання другої частини задачі.
Припустимо, що першу частину задачі буде вкрадено іншим потоком, він, у свою чергу, розіб'є першу підзадачу ще на дві підзадачі, і процес повторюватиметься, поки задачі не стануть досить малими для виконання без розбивки. Поріг, до якого слід розбивати задачі, рекомендується вибирати виходячи з наступної умови:
ThreshHold = N / (C*L), де N — це розмір задачі, L — так званий load factor. Це число має порядок від 10 до 100 — по суті це кількість задач, яку виконає один воркер, помножена на С — кількість воркерів у пулі.
Є кілька базових підходів для розподілу задач у threadpoll`ах:
- Work arbitrage — загальний арбітр роздає задачі. Наприклад, це черга задач ThreadPollExecutor. Є загальна черга задач, і воркери беруть із цієї черги задачі на виконання.
- Work dealing — воркер, що має дуже багато задач, передає задачі іншим потокам. У цьому способі є недолік: якщо потік завантажений, йому треба витрачати час на пошук вільних потоків замість виконання задач.
- Work stealing — якщо воркер не має задач на виконання, потік може вкрасти задачі з черги іншого потоку. Цей алгоритм використовується у Fork/Join poll. Також алгоритм крадіжки задач використовується для більш рівномірного перерозподілу задач між всіма потоками в пулі.
ForkJoinPoll приймає сутність ForkJoinTask за аналогією Runnable або Callable. Це абстрактний клас, він реалізує інтерфейс Future, і від цього класу успадковуються два класи RecursiveAction і RecursiveTask, які мають тільки один абстрактний метод compute(). Різниця між цими двома класами в тому, що RecursiveTask може повертати результат, а RecursiveAction нічого не повертає. RecursiveAction може, наприклад, використовуватися для сортування якихось значень. Приклад використання ForkJoinPool — у лістингу 10.
Лістинг 10:
public class ForkJoinPoolTest {
public static void main(String[] args) {
int[] array = yourMethodToGetData();
ForkJoinPool pool = new ForkJoinPool();
Integer max = pool.invoke(new FindMaxTask(array, 0, array.length));
System.out.println(max);
}
static class FindMaxTask extends RecursiveTask<Integer> {
private int[] array;
private int start, end;
public FindMaxTask(int[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if (end - start <= 3000) {
int max = -99;
for (int i = start; i < end; i++) {
max = Integer.max(max, array[i]);
}
return max;
} else {
int mid = (end - start) / 2 + start;
FindMaxTask left = new FindMaxTask(array, start, mid);
FindMaxTask right = new FindMaxTask(array, mid + 1, end);
ForkJoinTask.invokeAll(right, left);
int leftRes = left.getRawResult();
int rightRes = right.getRawResult();
return Integer.max(leftRes, rightRes);
}
}
}
}
У лістингу 10 замість виклику методів fork(), compute() і join () викликається метод ForkJoinTask.invokeAll(), який робить те саме, що і три ці методи. В лістингу 11 наведено приклад використання класу RecursiveAction. У програмі створюються вигадані продукти, їм призначаються імена, а потім у fork/join poll на них встановлюється ціна.
Лістинг 11:
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class Main {
public static void main(String[] args) throws InterruptedException {
List<Product> products = generate(10000);
Task task = new Task(products, 0, products.size());
ForkJoinPool pool = new ForkJoinPool();
pool.execute(task);
while (!task.isDone());
pool.shutdown();
if (task.isCompletedNormally()) {
System.out.print("Main: The process has completed normally.\n");
}
for (Product product : products) {
System.out.printf("Product %s: %d\n", product.getName(),
product.getPrice());
}
System.out.println("Main: End of the program.\n");
}
private static List<Product> generate(int size) {
return IntStream.rangeClosed(1, size)
.mapToObj(i -> {
Product product = new Product();
product.setName("Product " + i);
product.setPrice(10);
return product;
}).collect(Collectors.toList());
}
}
import java.util.List;
import java.util.Random;
import java.util.concurrent.RecursiveAction;
public class Task extends RecursiveAction {
private List<Product> products;
private int first;
private int last;
public Task(List<Product> products, int first, int last) {
this.products = products;
this.first = first;
this.last = last;
}
@Override
protected void compute() {
if (last - first < 10) {
updatePrices();
} else {
int middle = (last + first) / 2;
System.out.printf("Task: Pending tasks: %s\n", getQueuedTaskCount());
Task t1 = new Task(products, first, middle + 1);
Task t2 = new Task(products, middle + 1, last);
invokeAll(t1, t2);
}
}
private void updatePrices() {
Random random = new Random();
for (int i = first; i < last; i++) {
Product product = products.get(i);
product.setPrice((int) (Math.random() * (21 - 10 + 1) + 10));
}
}
}
public class Product {
private String name;
private int price;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
}
Для відносно невеликих задач наприкінці обчислення буде багато потоків, що очікують на методі join(). Щоб вирішити цю проблему, використовується клас CountedCompleter. Припустимо, що спільна задача розбита на дерево підзадач. При розбивці можна вказати, на скільки підзадач допустимо розбити поточну задачу чи підзадачу. Дочірніх задачі може бути дві, три або більше. Перед завершенням методу compute() обов'язково має бути викликаний метод tryComplete(). Після розбивки відомо, скільки для цієї задачі чи підзадачі утворилося дочірніх задач. Припустимо, якийсь воркер виконує підзадачу, яка не має підзадач. Потік розуміє, що дочірніх задач немає, та замість очікування на методі join() підіймається на задачу вище. Якщо для батьківської задачі виконані всі підзадачі, результати підзадач збираються разом. І так відбувається до завершення основної задачі. Для більш детального знайомства з класом CountedCompleter слід звернутись до документації Java.
Приклад програми використання CountedCompleter наведено в лістингу 12.
Лістинг 12:
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountedCompleter;
import java.util.concurrent.ForkJoinPool;
public class CountedCompleterExample {
public static void main (String[] args) {
List<BigInteger> list = new ArrayList<>();
for (int i = 3; i < 20; i++) {
list.add(new BigInteger(Integer.toString(i)));
}
ForkJoinPool.commonPool().invoke(
new FactorialTask(null, list));
}
private static class FactorialTask extends CountedCompleter<Void> {
private static int SEQUENTIAL_THRESHOLD = 5;
private List<BigInteger> integerList;
private int numberCalculated;
private FactorialTask (CountedCompleter<Void> parent,
List<BigInteger> integerList) {
super(parent);
this.integerList = integerList;
}
@Override
public void compute () {
if (integerList.size() <= SEQUENTIAL_THRESHOLD) {
showFactorial();
} else {
int middle = integerList.size() / 2;
List<BigInteger> rightList = integerList.subList(middle,
integerList.size());
List<BigInteger> leftList = integerList.subList(0, middle);
addToPendingCount(2);
FactorialTask taskRight = new FactorialTask(this, rightList);
FactorialTask taskLeft = new FactorialTask(this, leftList);
taskLeft.fork();
taskRight.fork();
}
tryComplete();
}
@Override
public void onCompletion (CountedCompleter<?> caller) {
if (caller == this) {
System.out.printf("completed thread : %s numberCalculated=%s%n",
Thread.currentThread().getName(), numberCalculated);
}
}
private void showFactorial () {
for (BigInteger i : integerList) {
BigInteger factorial = calculateFactorial(i);
System.out.printf("%s! = %s, thread = %s%n", i, factorial,
Thread.currentThread().getName());
numberCalculated++;
}
}
private BigInteger calculateFactorial(BigInteger n) {
BigInteger ret = BigInteger.ONE;
for (int i = 1; i <= n; ++i) {
ret = ret.multiply(n);
}
return ret;
}
}
}
У лістингу 12 CountedCompleter використовується для обчислення факторіалів чисел від 3 до 20. Оскільки використовується тільки обчислення факторіала та значення не повертається, клас CountedCompleter типізується типом Void. Клас FactorialTask перевизначає метод compute() і метод onCompletion(CountedCompleter<?>Caller). Наприкінці методу compute() викликається метод tryComplete() для спроби завершення виконання задачі, відповідно, мають завершитись і підзадачі, якщо вони є. Метод onCompletion(CountedCompleter<?>Caller) викликається для задачі, яку було виконано та не було розбито на підзадачі. Такий підхід використовується у стрімах для паралельної обробки даних.



