
Video demo
Así es como se crea el asistente de Inteligencia Artificial (IA). Recomendamos leer primero las instrucciones y luego ver el video. Al final, también encontrarás un cuestionario en Kahoot: puedes hacerlo después de revisar el material o empezar directamente por ahí si ya te sientes seguro con el tema.
Por qué elegimos AWS Bedrock
En un proyecto para una importante empresa financiera del Reino Unido, nuestro product owner nos dijo que el chatbot existente no estaba cumpliendo con las expectativas de los usuarios. Los principales problemas eran claros:
- Resultados de búsqueda inexactos: el chatbot devolvía respuestas incorrectas con frecuencia, lo que incrementaba la carga de trabajo del equipo de operaciones, un problema que se agravaba a medida que crecía la base de usuarios.
- Falta de contexto: a pesar de contar con numerosas respuestas predefinidas, las sugerencias solían ser irrelevantes para las consultas de los usuarios.
- Actualizaciones lentas: no éramos propietarios de la solución actual, por lo que incluso cambios menores podían tardar semanas o meses en implementarse.
Ante estos desafíos, nos propusimos construir un chatbot rápido, confiable y de bajo mantenimiento, capaz de ofrecer respuestas precisas y contextuales.
Búsqueda léxica vs. búsqueda semántica
La búsqueda léxica (o búsqueda por palabras clave) es un método tradicional que compara las palabras o frases exactas de la consulta del usuario. En su forma más simple, se limita a coincidir palabras clave específicas sin procesamiento adicional, priorizando coincidencias exactas o variantes cercanas dentro de un texto.
Es el enfoque utilizado por herramientas tradicionales como Elasticsearch o Solr, que aplican técnicas como similitud de cadenas, tokenización y N-gramas.
La búsqueda semántica va un paso más allá. Comprende el significado y la intención detrás de las consultas mediante modelos de machine learning (generalmente redes neuronales) que codifican el texto en embeddings vectoriales dentro de un espacio multidimensional. Esto permite encontrar resultados relevantes incluso cuando las palabras clave no coinciden de forma exacta.
La búsqueda semántica se destaca en la comprensión de sinónimos, significados y conceptos relacionados. Además, resulta especialmente eficaz con datos no estructurados e incluso puede manejar formatos como imágenes.
Explorando opciones: Ollama vs. AWS Bedrock
Opción 1: Ollama
Para la búsqueda semántica, primero evaluamos Ollama, una herramienta open source que permite ejecutar LLMs de forma local. Es ideal para organizaciones que priorizan el control de los datos y la privacidad. Al ejecutar los modelos localmente, se mantiene la propiedad total de la información y se evitan posibles riesgos de seguridad asociados al almacenamiento en la nube.
Pros:
- Control total del modelo de IA
- Puede desplegarse mediante Docker
Contras:
- Costos de mantenimiento más altos que los servicios en la nube
- Requiere una infraestructura significativa y personal dedicado para el procesamiento y monitoreo de datos
- El mantenimiento del almacenamiento vectorial es complejo
Dado nuestro cronograma ajustado y la necesidad de reducir el mantenimiento, Ollama no era la opción adecuada para este proyecto.
Opción 2: AWS Bedrock
Evaluamos distintos servicios en la nube (Azure, Google y AWS) y finalmente elegimos AWS Bedrock, aprovechando la experiencia previa de nuestro equipo en AWS. Se trata de un servicio totalmente administrado que ofrece modelos fundacionales (FMs) de alto rendimiento de empresas líderes en IA como Anthropic, Cohere, DeepSeek, Luma, Meta, Mistral AI y Amazon, todo a través de una única API.
Además, incluye un conjunto amplio de capacidades necesarias para crear aplicaciones de IA generativa con foco en seguridad, privacidad y uso responsable de la IA.
Alternativas: Azure OpenAI, Google Vertex AI
Pros:
- Servicio completamente administrado (no es necesario dockerizar ni desplegar modelos internamente)
- Altos niveles de rendimiento y cumplimiento
- Ciclos de desarrollo rápidos con una mínima configuración
Contras:
- Control limitado sobre el sistema
- Vendor lock-in, lo que puede dificultar futuras migraciones a otras plataformas
Configuración de AWS Bedrock
Configuración del lado del servidor
- Elige una fuente de datos
AWS Bedrock admite múltiples fuentes de datos:- Buckets S3: adecuados para documentos o archivos estáticos
- Web Crawler: permite rastrear páginas web interconectadas e incorporarlas a la base de datos vectorial
- Páginas de Confluence: ideales para bases de conocimiento organizacionales que se actualizan con frecuencia
- Configura un almacén vectorial
En otras palabras, elige dónde se almacenarán los datos. AWS admite OpenSearch Serverless, que ofrece alto rendimiento pero es bastante costoso. Como alternativa, puedes usar PostgreSQL con plugins vectoriales. - Selecciona el modelo de embeddings
Es importante que elijas el modelo con cuidado, teniendo en cuenta la disponibilidad en la región. No todas las regiones de AWS admiten todos los modelos de embeddings debido a políticas o regulaciones. - Sincroniza los datos
Con solo presionar el botón de sincronización, todos los datos definidos en la fuente se procesan automáticamente.
Nota: no es posible crear bases de conocimiento utilizando la cuenta root de AWS. Es necesario crear usuarios adicionales con permisos específicos para Bedrock.
Opciones del lado del cliente
- En Python, el AWS SDK (Boto3) está bien soportado y es sencillo de usar.
- En Java, existe el AWS SDK, pero la documentación para Bedrock es limitada.
- Otras librerías: se pueden explorar Spring AI, LangGraph, o LangChain, según tus necesidades.
Recomendamos trabajar con Python. En nuestro caso, buscábamos una solución simple, por lo que no implementamos un chatbot con historial de conversaciones. El foco estuvo en recuperar datos, con un leve enriquecimiento antes de mostrarlos al usuario.
Costos
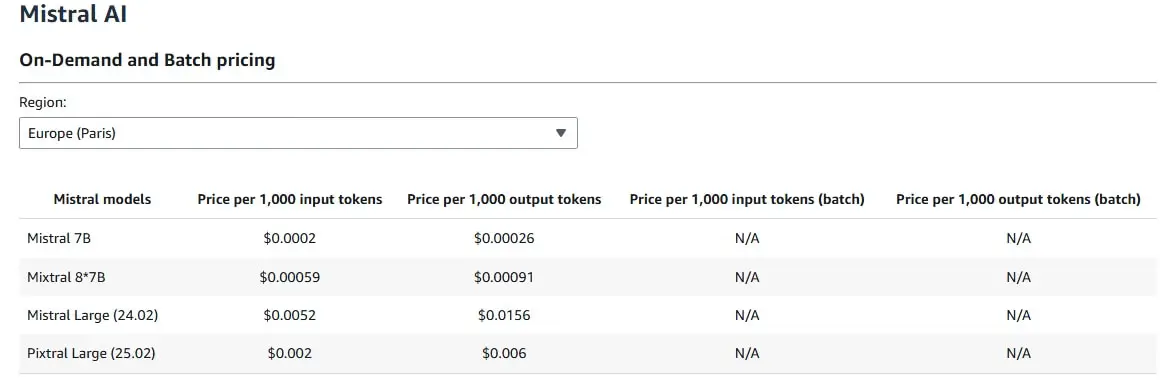
Los costos varían según la región y el modelo utilizado. Para nuestro PoC, usamos Mistral 7B, y un mes de OpenSearch tuvo un costo aproximado de USD 100. En la imagen a continuación se puede ver que, para 1000 tokens, el costo no es elevado.
Algunas empresas pueden preferir utilizar una alternativa a la solución predeterminada de Amazon. Pero si esto no es un problema, recomendamos optar directamente por la solución de Amazon.
Próximos pasos
Una vez completada la implementación de AWS Bedrock, sigue esta guía para mejorar su rendimiento:
- Implementa protecciones alineadas con los requisitos de tu aplicación y con las políticas de IA responsable mediante Amazon Bedrock Guardrails.
- Prueba almacenes vectoriales alternativos.
- Testea diferentes prompts.
- Agrega capacidades de chat y agentes.
Cuestionario
Ahora, veamos cuánto sabes sobre asistentes de IA.
Conclusión
AWS Bedrock ofrece un camino eficiente y totalmente administrado para crear asistentes de IA capaces de brindar respuestas relevantes y contextuales. Con una selección cuidadosa de modelos, una configuración estructurada y un proceso continuo de optimización, se posiciona como una opción sólida para organizaciones que buscan desplegar sistemas de IA robustos de forma rápida y con una carga operativa mínima.







